Prepare Data
Loading Data into CAT
You can upload and code a “raw dataset” from a file with text formatted in one of three ways:
- a plain text file (.txt)
- a zip archive of plain text files (.zip), or
- an XML file (.xml)
Data Preparation When Using a Single Plain Text File
CAT relies on predefined spans of text to enable the auto-loading of discrete items or what we call "codeable units" during the coding process. Unless you use one of two special delimiters, the system assumes you want to apply your codes to the entire document. If you upload a single plain-text file, the coding system will present the codeable units one at a time consisting of the text lying in between each pair of blank lines. The blank link is the delimiter. Please note: this blank line delimiter is only for the case of the single text file dataset.
When uploading a single .txt file as your raw data, prepare it as follows:
<text to be coded><hard return>
<hard return>
<text to be coded><hard return>
<hard return>
Data Preparation When Using a .zip Archive of Plain Text Files
If you upload a collection of plain text files in a .zip archive, the system assumes that each document is a "codeable unit." You can, however, insert a special delimiter in your raw data:
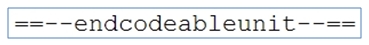
This delimiter allows you to upload a .zip archive of two or more files and still code at the sub-document level, rather than whole document level. As with the single text file, the span of text to be coded is up to you (e.g., a sentence, a question/answer pair, a paragraph, a speaker in a focus group, etc.). The delimiter has to be on a line all by itself - that is, you need to have:

Note: Be sure to save your raw data files as “plain text” (.txt) files. Data Preparation using an XML File
The system will verify that it conforms to the correct schema definition and process the file as such. This schema may be found at:
http://cat.texifter.com/resources/codeupload.xsd
A sample XML document and tips on using the XML upload functionality can be found at: http://cat.ucsur.pitt.edu/resources/codeupload.xsd
Codeable units can be defined in ATLAS.ti as "free quotations" and loaded into CAT for coding via xml export. This is useful if coding at the sentence or multiple sentence level since the CAT interface reduces errors and decreases coding time relative to ATLAS.ti.
The following procedure illustrates how to export all of the quotations from an HU as codeable units in CAT.
- Define free quotations within your HU In any primary document, select a span of text, right click and select "Create Free Quotation." Repeat as necessary.
- Export the HU as an XML file In ATLAS.ti (6.1.17): Tools » XML » Export HU to XML. Select “Also include Quotations contents (as plain text).” These will become CAT's codeable units. Send the output to a file and remember its name and location.
-
Convert ATLAS.ti XML schema into that required by CAT There are presumably many ways to complete this step, but a simple method uses Microsoft Excel.
- Go to the “Developer” tab on the ribbon. If the Developer tab is not there follow these instructions to activate it.
- Select “Import” and navigate to the ATLAS.ti export. Hit OK through the one (or two) dialogs that follow.
- The text of each free quotation in ATLAS.ti is stored as a separate row in the Excel table (in the column labeled “p”) along with many other variables. In order to export, these other variables must be removed. Delete all columns except for the one containing the quotation text. Depending on your analysis needs, it might be useful to concatenate parts of the filename to the beginning of quotation text, creating an identifier that could be used to link each quotation to its parent document.
- Export the resultant xml file from the developer tab and load the text of this file into a word processor.
-
Now XML tags simply need to be renamed/removed as appropriate to match CAT's requirements. In each case below 'find' the ATLAS.ti tag to the left of the arrow and 'replace' it with the CAT tag to the right of the arrow using a macro or repeated use of the “Replace” function.
- <p> » <![CDATA[ …|CDATA[...]">…">CDATA[ …> (Where the content of the quotation replaces the ellipsis.)
- <content> » <itemtext>
- <q> » <item>
- <quotations> » <items>
- <storedHU> » <rawcodefile>
-
Delete the <primDoc> and <primDocs> tags and insert the header after the <rawcodefile> tag as follows:
<codefileheader> <datasetname>Test xml dataset</datasetname> </codefileheader>
- Upload the resultant file to CAT and begin coding!